使用Feign Hystrix做熔断器
熔断作用在服务调用的一端,要实现熔断器, 只需在服务消费者(eureka-consumer)上做改动就行。
Feign中已经依赖了Hystrix所以在maven配置上不用做任何改动。
修改配置文件
spring: |
创建一个回调方法类
创建 HelloRemoteHystrix 类实现 HelloRemote 中实现回调的方法
|
设置fallback属性
在HelloRemote类添加指定 fallback 类,在服务熔断的时候返回 fallback 类中的内容。
|
代码部分,到此为止就ok了。
测试
启动三个项目(注册中心、服务提供者、服务消费者)
访问http://localhost:28085/hello/zhangsan返回结果:
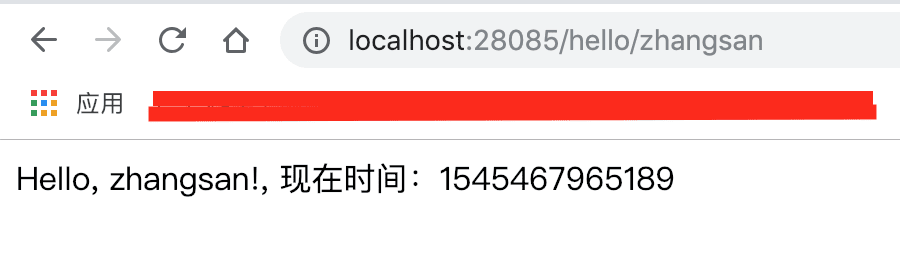
可以看到当前是正常返回结果的,这个时候,把服务提供者的服务kill掉,再次访问http://localhost:28085/hello/zhangsan,返回结果:
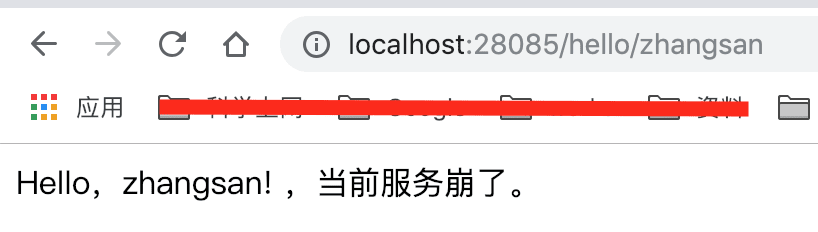
说明熔断成功!
雪崩效应
这段摘自纯洁的微笑博客
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
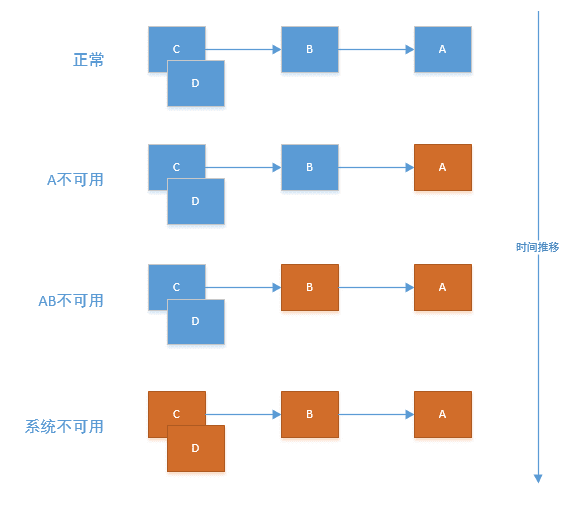
如果下图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。
熔断器
这段摘自纯洁的微笑博客
熔断器的原理很简单,如同电力过载保护器。它可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
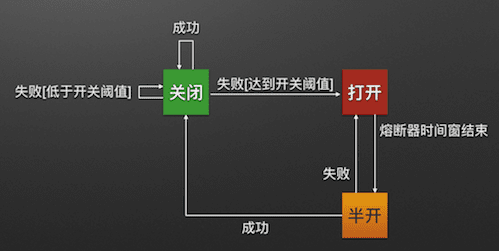
熔断器模式就像是那些容易导致错误的操作的一种代理。这种代理能够记录最近调用发生错误的次数,然后决定使用允许操作继续,或者立即返回错误。 熔断器开关相互转换的逻辑如下图:
熔断器就是保护服务高可用的最后一道防线。
Hystrix特性
断路器机制
断路器很好理解, 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力.
Fallback
Fallback相当于是降级操作. 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存.
资源隔离
在Hystrix中, 主要通过线程池来实现资源隔离. 通常在使用的时候我们会根据调用的远程服务划分出多个线程池. 例如调用产品服务的Command放入A线程池, 调用账户服务的Command放入B线程池. 这样做的主要优点是运行环境被隔离开了. 这样就算调用服务的代码存在bug或者由于其他原因导致自己所在线程池被耗尽时, 不会对系统的其他服务造成影响. 但是带来的代价就是维护多个线程池会对系统带来额外的性能开销. 如果是对性能有严格要求而且确信自己调用服务的客户端代码不会出问题的话, 可以使用Hystrix的信号模式(Semaphores)来隔离资源.
总结
通过使用 Hystrix,我们能方便的防止雪崩效应,同时使系统具有自动降级和自动恢复服务的效果。