Spring Cloud Sleuth
一般的,一个分布式服务跟踪系统主要由三部分构成:
- 数据收集
- 数据存储
- 数据展示
根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(Trouble Shooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
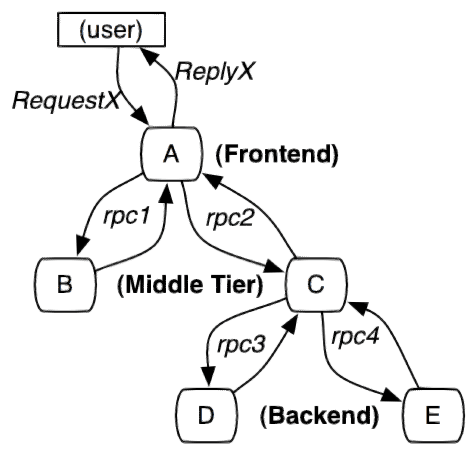
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个trace。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个span。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过
Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时; - 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
这是Spring Cloud Sleuth的概念图:
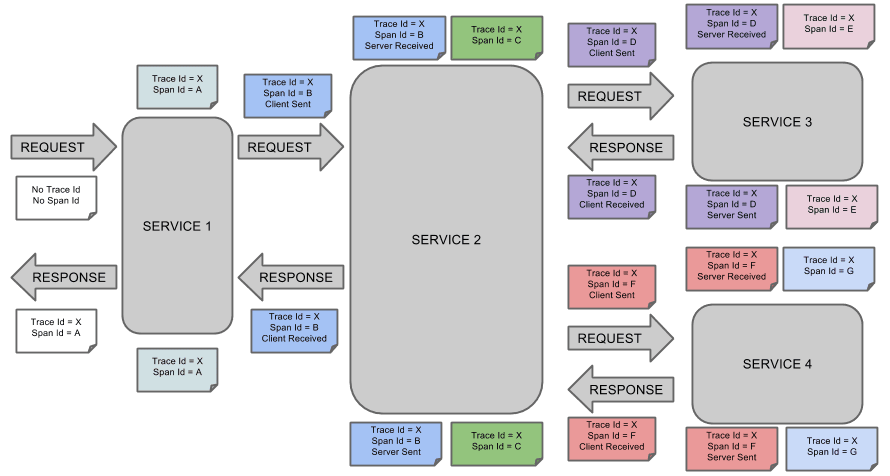
ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。
实践
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用。
客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ。
准备工作
无论是用HTTP的方式还是消息总线的方式,都需要:
- 一个注册中心,用之前的就行
- 一个Zipkin服务端
- 两个微服务应用,
trace-a和trace-b,其中trace-a中有一个 REST 接口/trace-a,调用该接口后将触发对trace-b应用的调用。
Zipkin服务端
使用Docker:
pull image
docker pull openzipkin/zipkin
run container
docker run -d -p 9411:9411 openzipkin/zipkin
启动后,访问http://localhost:9411/zipkin/就能看到如下界面:
服务端OK。
微服务应用
创建两个基本的Spring Boot工程,分别名为trace-a和trace-b。
pom配置
两个工程的pom文件配置都引入以下依赖:
<dependencies> |
配置文件
两者的配置文件也一样(除了spring. application.name和server.port,自行修改)
spring: |
Spring Cloud Sleuth 有一个 Sampler 策略,可以通过这个实现类来控制采样算法。采样器不会阻碍 span 相关 id 的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth 默认采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的采样比例为: 0.1(即 10%)。不过我们可以通过
spring.sleuth.sampler.percentage来设置,所设置的值介于 0.0 到 1.0 之间,1.0 则表示全部采集。
编码
对trace-a和trace-b进行编码。
trace-a
配置一个WebClient Bean:
|
创建一个TraceAController:
|
trace-b
trace-b的启动类如下,使用默认的代码,不需修改:
|
创建一个TraceBController:
|
至此,准备工作就完成了。*Spring 应用在监测到 classpath 中有 Sleuth 和 Zipkin 后,会自动在 WebClient(或 RestTemplate)的调用过程中向 HTTP 请求注入追踪信息,并向 Zipkin Server 发送这些信息。*
验证
分别启动服务注册中心、trace-a和trace-b,访问http://localhost:28092/trace-a,可以得到返回值Trace.,同时在两个工程的控制台都能看到相关日志输出:
trace-a工程控制台 |
访问http://localhost:9411,点击Find Traces看到有一条记录:
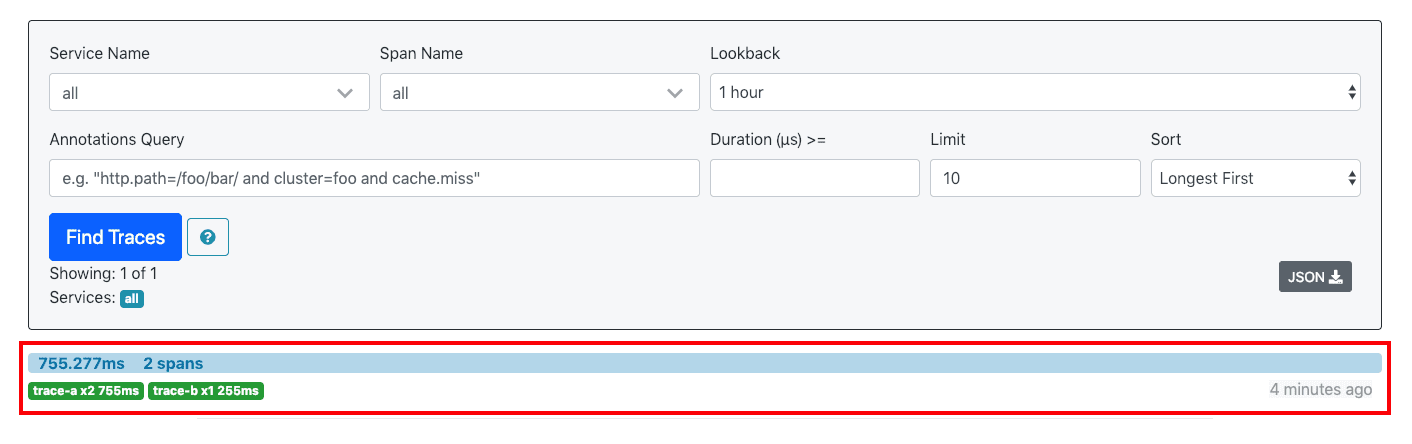
点击进去可以看到详细信息:
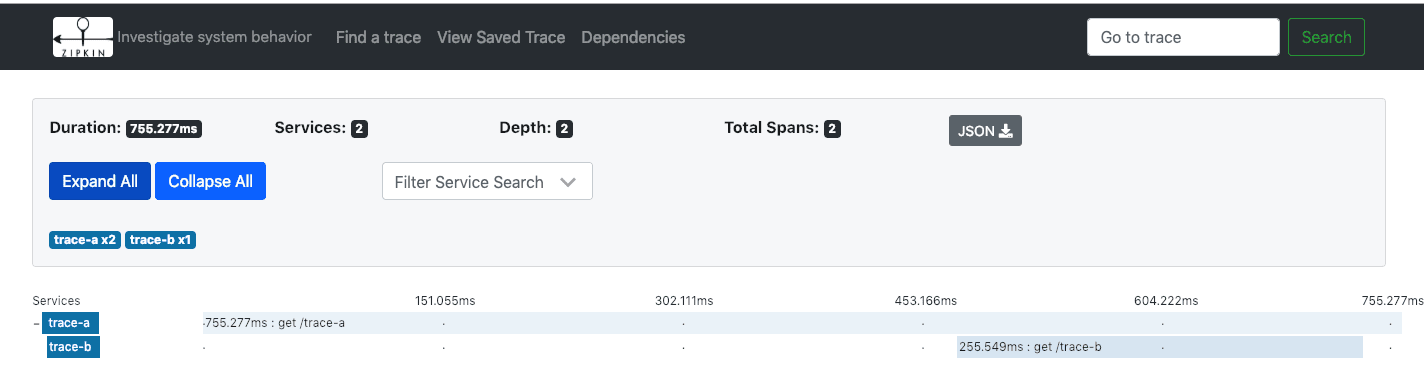
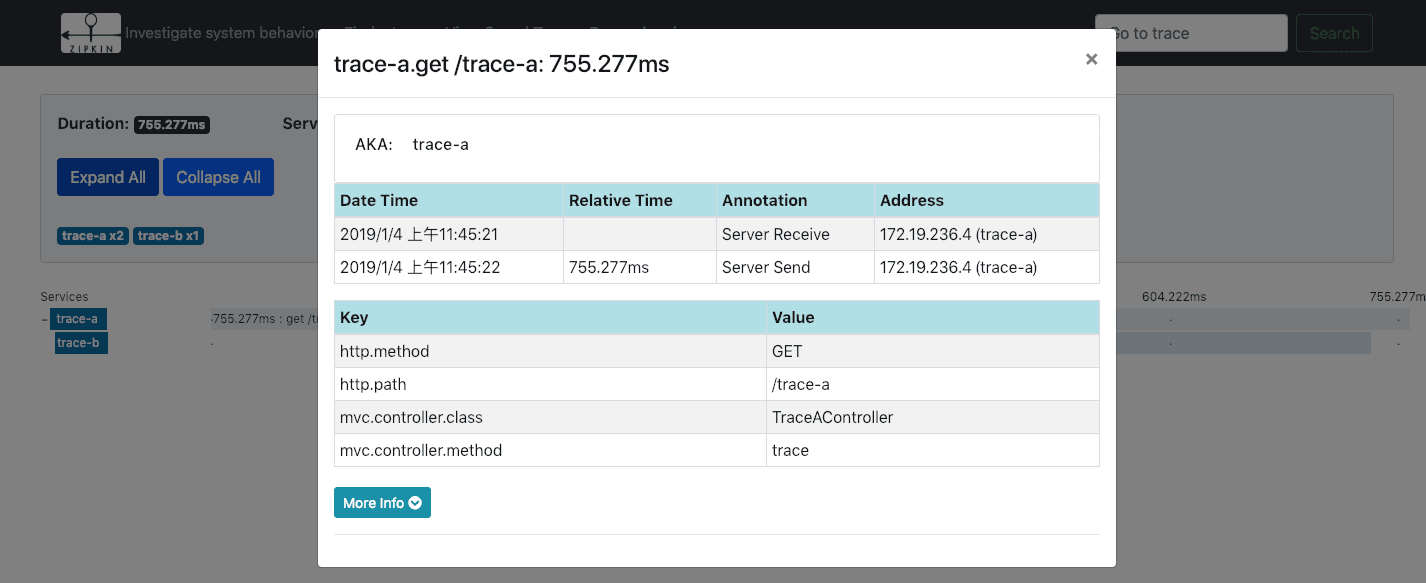
消息总线-RabbitMQ方式
Zipkin 不再推荐我们来自定义 Server 端了,所以在最新版本的 Spring Cloud 依赖管理里已经找不到 zipkin-server 了。
通过环境变量让Zipkin从RabbitMQ中读取信息:
RABBIT_ADDRESSES=localhost java -jar zipkin.jar |
关于 Zipkin 的 Client 端,也就是微服务应用,我们就在之前 trace-a、trace-b 的基础上修改,只要在他们的依赖里都引入spring-cloud-stream-binder-rabbit就好了,别的不用改。
<dependency> |